
Tutorials
Schedule
Saturday April 2, 2011
| T. BOURRIT | P. PAYOT | I. STRATON | SAMIVEL | G. LOPPE | J. VALLOT | |
|---|---|---|---|---|---|---|
| Morning 08:00-12:00 |
GCC | Parallel | WIR-1 | ODES-9 | ||
| Afternoon 14:00-18:00 |
AlphaZ | LoopVect | WISH-3 | X10 |
Sunday April 3, 2011
| T. BOURRIT | P. PAYOT | I. STRATON | SAMIVEL | G. LOPPE | J. VALLOT | |
|---|---|---|---|---|---|---|
| Morning 08:00-12:00 |
GROW-3 | IMPACT-1 | SMART-5 | Pin! | WCC | |
| Afternoon 14:00-18:00 |
ArBB | ACCA-1 | DyRIO | PIPS |
| Rooms: |
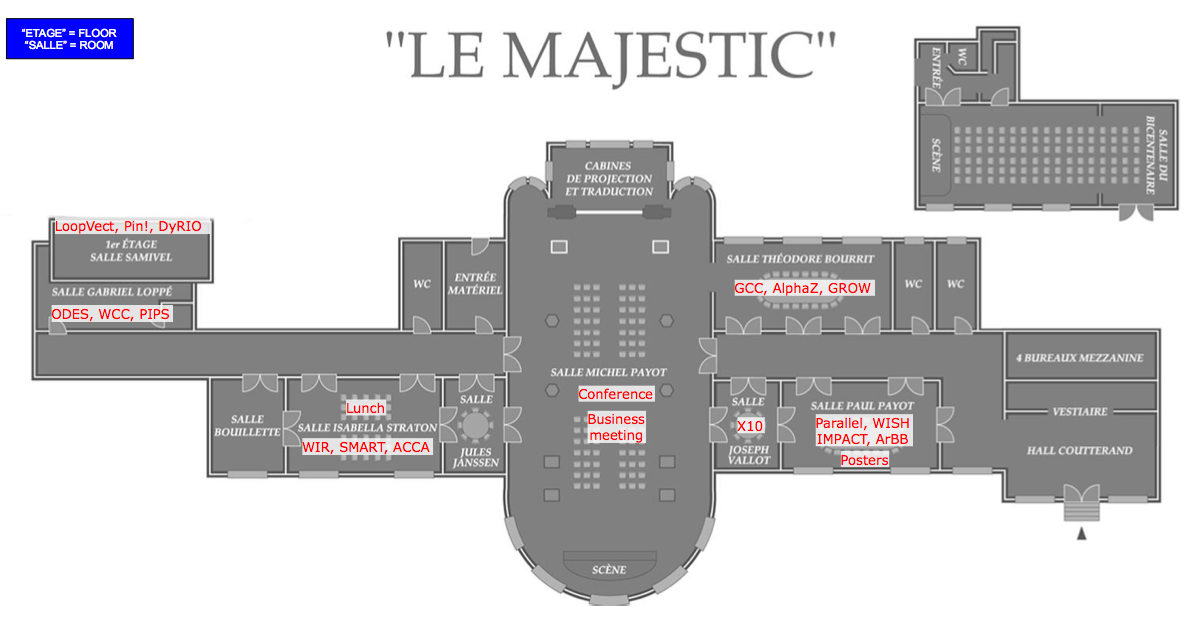
|
[ArBB] Array Building Blocks: A Dynamic Compiler for Data-parallel Heterogeneous Systems
summary:
Hardware platforms are getting harder to program effectively, as they grow in
complexity to include multiple cores, SIMD hardware, accelerators (e.g. GPUs and
Intel's Knights Ferry - formerly Larrabee) and even clustering support. The
challenge is to provide an efficient means of exploiting parallel performance to
the masses of novice programmers. At least two things are required to solve
this problem: 1) a language interface that enables ease of use without the
perils of parallel programming, and 2) a compiler infrastructure that takes a
high-level specification of what to do, and portably maps it onto a variety of
heterogeneous hardware targets.
This tutorial uses Intel's newly-released Array Building Blocks (ArBB) to
illustrate the challenges and potential solutions in this space. ArBB is a
dynamic compiler infrastructure that can compile or JIT for both SIMD and thread
parallelism on symmetric multi-processor, distributed, and accelerator
targets. Parallelism is exposed to this infrastructure via an embedded
language, e.g. a library-based C++ API, using aggregate data types and
operators. It enables safety and debuggability by construction. It allows
applications with kernels that are recoded with minimized effort to be compiled
once using standard compilers, and then be dynamically retargeted to platforms
that haven't even been invented yet by simply switching runtime libraries. We
put ArBB in the context with a variety of other programming models, including
CUDA and OpenCL.
This tutorial may be of practical interest to language experts who are
interested in parallel language design, to educators who may want to leverage
this material to teach parallel programming models for emerging architectures,
and to practitioners who may benefit from our experience implementing compilers
to address customer-driven concerns. The presentation of new language features,
application examples, optimization techniques that enable efficient offload to
accelerators, and the demonstration of speedup and debugging support on both
standard laptops and pre-production acceleration hardware are some of the
aspects of this tutorial that could draw participation.
More details
presenters:
Chris J. Newburn (CJ), Intel
[DyRIO] Building Dynamic Instrumentation Tools with DynamoRIO
summary:
This tutorial will present the DynamoRIO tool platform and describe how
to use its API to build custom tools that utilize dynamic code
manipulation for instrumentation, profiling, analysis, optimization,
introspection, security, and more. The DynamoRIO tool platform was first
released to the public in June 2002 and has since been used by many
researchers to develop systems ranging from taint tracking to prefetch
optimization. DynamoRIO is now publicly available in open source form.
The first part of the tutorial will consist of presentations that
describe the full range of DynamoRIO's powerful API, which abstracts away
the details of the underlying infrastructure and allows the tool builder
to concentrate on analyzing or modifying the application's runtime code
stream. We will give many examples and highlight differences between
DynamoRIO and other tool platforms. We will also seek feedback on how we
can improve the DynamoRIO API.
The second part of the tutorial will include lab sessions where attendees
experiment with building their own tools using DynamoRIO. Attendees for
should bring a laptop with a Linux or Windows development environment:
gcc on Linux, Visual Studio on Windows, as well as CMake (which can be
installed at the tutorial if necessary).
More details
presenters:
Derek Bruening
Qin Zhao
[GCC] Essential Abstractions in GCC
summary:
The GNU Compiler collection is a compiler generation framework which constructs
a compiler for a given architecture by reading the machine descriptions for that
architecture. This framework is practically very useful as evidenced by the
existence of several dozens of targets for which compilers have been created
using GCC. These compiler are routinely used by millions of users for their
regular compilation needs. While a deployment of GCC on the default parameters
is easy, any other customization, experimentation and modification of GCC is
difficult and requires a high amount of expertise and concentrated efforts. In
this tutorial we describe some carefully chosen abstractions that help one to
understand the retargetability mechanism and the architecture of the compiler
generation framework of GCC and relate it to a generated compiler.
A summary of topics covered:
- meeting the challenge of understanding GCC
- the architecture of GCC
- generating a compiler from GCC
- the structure of a GCC generated compiler
- first level graybox probing of the compilation sequence of a GCC generated compiler
- plugin structure of GCC to hook in front ends, optimization passes, and back end
- introduction to machine descriptions
- retargetability and instruction selection mechanism of GCC
presenters:
Uday P. Khedker
[Parallel] GPU Programming Models, Optimizations and Tuning
summary:
GPU based parallel computing is of tremendous interest today because of their
significantly higher peak performance than general-purpose multicore
processors,
as well as better energy efficiency. However, harnessing the power of GPUs is
more complicated than general-purpose multi-cores. There has been considerable
recent interest in two complementary approaches to assist application
developers:
- programming models that explicitly expose the programmer to parallelism; and
- compiler optimization and tuning frameworks to automatically transform programs for parallel execution on GPUs.
More details
presenters:
J. (Ram) Ramanujam, Department of Electrical and Computer Engineering, Louisiana State University
P. (Saday) Sadayappan, Department of Computer Science and Engineering, Ohio State University
[Pin!] Detailed Pin!
summary:
Pin is a dynamic instrumentation system provided by Intel
(http://www.pintool.org), which allows C/C++ introspection code to be injected
at arbitrary places in a running executable. The injected introspection code is
referred to as a Pin tool and is used to observe the behavior of the program.
Pin tools can be writtten to perform various functionalities including
application profiling, memory leak detection, trace generators for the IA32,
Intel64 and IA64 (Itanium) platforms, running either Windows or Linux. Pin
provides a rich API that abstracts away the underlying instruction set
idiosyncrasies and allows context information such as register contents to be
passed to the injected code as parameters. Pin automatically saves and restores
registers that are overwritten by the injected code so the application continues
to execute normally. Pin makes it easy to do studies on complex real-life
applications, which makes it a useful tool not only for research, but also for
education. Pin has been downloaded tens of thousands times, has been cited in
over 700 publications, and has over 550 registered mailing list users.
The tutorial targets researchers, students, and educators alike, and provides a
detailed look at Pin, both how to use Pin and how Pin works. Participants will
obtain a good undersanding of the Pin API ans. The tutorial is comprised of four
learning components. The first component provides insight into the workings of
Pin, and introduces its fundamental instrumentation structures and concepts thru
example Pin tools. The second component will present methods and considerations
for writing optimal Pintools. The third component introduces useful Pin-based
tools that are freely available for download, in particular we will look in
detail at the memtrace and membuffer tools, which implement the instrumentation
basis for algorithms which need to examine memory accesses. The fourth component
will present some of the more advanced Pin APIs, such as signal/exception
interception, multi threaded pin tools, Pin interface to debuggers.
More details
presenters:
Tevi Devor, Staff Engineer, Intel
Robert Cohn, Senior Principal Engineer, Intel
[PIPS] PIPS: An Interprocedural Extensible Source-to-Source Compiler Infrastructure for Code/Application Transformations and Instrumentations
summary:
The PIPS compiler framework was designed in 1988 at MINES ParisTech to
research interprocedural parallelization. It has been used to generate
automatic code distribution, OpenMP-to-MPI code translation, HPF
Compiler, automatic C and Fortran to CUDA translation, code
modelization for graphic IDEs, genetic algorithm-based optimizations,
SIMD (SSE, AVX...) portable code generation and code optimization for
FPGA-based accelerators. PIPS supports entire Fortran 77 and C
applications and is easily extensible. After 20 years of development
and constant improvement, PIPS is a robust source-to-source compiler,
providing a large set of program analyses and transformations with
around 300 phases.
More details
presenters:
Corinne Ancourt, Centre de Recherche en Informatique, MINES ParisTech, France
Serge Guelton, Telecom Bretagne/Info/HPCAS, France
Ronan Keryell, CSO, HPC Project, France
Frederique Silber-Chaussumier, Telecom Sud Paris, France
[AlphaZ] AlphaZ and the Polyhedral Equational Model
summary:
The polyhedral model is now established as a powerful, "domain-specific"
model for program representation, analysis, and transformation. It is limited
to a small domain (commonly called affine-control loops) for which it provides
a very powerful abstraction. This tutorial will present, in a hands-on manner
two aspects of the model that are not very widely known. The first is the
*equational* aspect of the polyhderal model, where high level equations are
used to describe polyhderal computations, and the powerful static analyses
that are enabled by this declarative view. The second is exposure to an open
source, research tool, AlphaZ that is designed in a modular maner to be very
highly extensible. Participants will have the opportunity to write simple
program transformations themselves.
More details
presenters:
S. Rajopadhye, Colorado State University
[LoopVect] Program Optimization through Loop Vectorization
summary:
Most modern microprocessors contain vector extension that benefit from the fine
grain parallelism of vector operations. Programmers can take advantage of these
extensions through vectorizing compilers or by explicitly programming them with
intrinsics. A significant fraction of the peak performance of many of today's
machines can be attributed to their vector extensions.
This tutorial covers techniques to make the best possible use of vector
extensions. We will discuss:
- Compiler limitations and the manual transformations that the programmer must apply to overcome compiler limitations.
- The use of intrinsics to explicitly program vector extensions.
More details
presenters:
Maria J. Garzaran, Research Assistant Professor, Computer Science Department University of Illinois at Urbana-Champaign
David Padua, Donald Biggar Willet Professor, Computer Science Department University of Illinois at Urbana-Champaign
[WCC] Reconciling Compilers and Timing Analysis for Safety-Critical Real-Time Systems - the WCET-aware C Compiler WCC
WARNING: tutorial canceled due to personal emergency for one of the organizers - our apologies
summary:
Timing constraints must be respected for safety-critical real-time
applications. Traditionally, compilers are unable to use precise estimates of
execution times for optimization, and timing properties of code are derived
after compilation. A number of design iterations are required if timing
constraints are not met. We propose to reconcile compilers and timing analysis
and to create a worst-case execution time (WCET) aware compiler in this way.
Such WCET-aware compilers can exploit precise WCET information during
compilation. This way, they are able to improve the code quality. Also, we may
be able to avoid some of the design iterations.
In this tutorial, we present the integration of a compiler and a WCET
analyzer, yielding our WCET-aware compiler WCC. We are then considering
compiler optimizations for their potential to reduce the WCET, assuming that
the WCET is now used as the cost function. Considered optimizations include
loop unrolling, register allocation, scratchpad memory allocation, memory
content selection and cache partitioning for multi-task systems. For large
sets of benchmarks, average WCET reductions of up to 40% were achieved. The
results indicate that this new area of research has the potential of achieving
worthwhile execution time reductions for safety-critical real-time code.
More details
presenters:
Heiko Falk, TU Dortmund, Germany
Peter Marwedel, TU Dortmund, Germany
[X10] Inside X10: Implementing a High-level Language on Distributed and Heterogeneous Platforms
summary:
X10 is a type-safe, modern, parallel, distributed
object-oriented language designed specifically to address the
challenges of productively programming complex hardware systems
consisting of clusters of multicore CPUs and accelerators.
A single X10 source program can be compiled for efficient
execution on a wide variety of target platforms including single
machines running Linux, MacOS, or Windows; clusters of x86 and
Power based SMP nodes; BlueGene/P supercomputers; and
CUDA-enabled GPUs.
Implementing a high-level language like X10 on a variety of
platforms and achieving high performance presents a number of
challenges. In this tutorial we will briefly cover the core
features of the X10 language and some current empirical
results, but will mainly focus on presenting the implementation
technology that underlies the system. Topics covered will
include:
- an overview of the X10 compiler and runtime system
- a generalization of Cilk-style workstealing for non-strict task graphs
- compilation of X10 to CUDA-enabled GPUs
- optimization of specific X10 language features
More details
presenters:
Olivier Tardieu, IBM Research
David Cunningham, IBM Researchu
Igor Peshansky, IBM Research